Main window
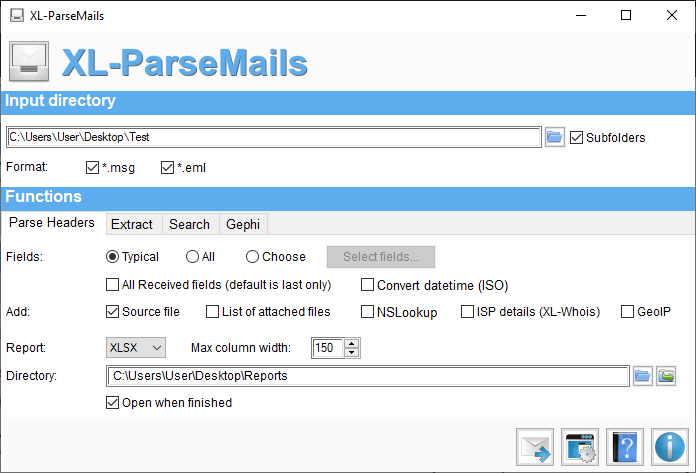
The main window is divided in three sections:
- Input: Input must be a folder that contains .msg and .eml files. You can include subfolders or not.
- Functions: Action to apply on selected files. See Functions section for details.
- Footer: The footer contains information about the state of the process and buttons: Process, Settings, Documentation and About. When the Process is disabled, you can move your mouse over the Not Ready? Look Here to see message what is missing.
Functions
There are four tabs: Parse Headers, Extract, Search and Gephi.
Parse Headers
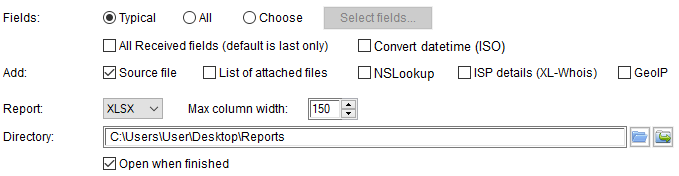
Parse and extract fields from email headers and generate a table report (XLSX, HTML or CSV). Options:
- Fields: You can select:
- Typical: Preselected fields that can be set in Settings.
- All: A column is created for any field that is found. You should get a very big table, but you won't loose anything!
- Choose: Select the fields you want from a list. You can also select the order of the fields.
- All Received fields: If you check this option, all received field values will be included and numeroted in the results. Default is to keep the last received value only, which is presumed to be the first in the SMTP communication as you may know.
- Convert datetime (ISO): In a email header, date and time may be provided in multiple timezones. If you check this option, all datetimes will be replaced by their ISO representation in local timezone (ex.: 2010-01-01 12:55:28 -0400). This format is easily recognized by other tools like spreadsheets. The local timezone can be changed in Settings.
- Add: Add columns to the table:
- Source file: It will be the first column. It contains the email file path.
- List of attached files: List of all attachments in the email.
- Nslookup: A host or domain name for each parsed public IP address. An active internet connection is required for this option.
- ISP details: ISP for each parsed public IP address. You must have a valid XL-Whois database to use this option.
- GeoIP: GeoIP details for each parsed public IP address. You must have a valid GeoIP database to use this option.
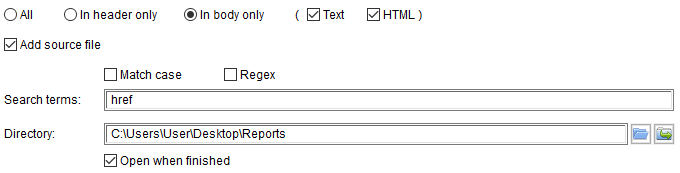
Report: This is the folder where the report will be saved. The folder is automatically saved. Available report formats are XLSX, HTML or CSV. For XLSX, you can set the maximum width of a column. Wrap text will be used to show all the data. For CSV, you can choose the separator to use (tabulation, ,, ; or |).




Settings
General

- In Tool section, we have the following functions and options:
- Open user dir: This is the directory where settings are saved. Copy the content of this directory if you want to backup your settings.
- Check Update: Check on le-tools.com if a tool update is available.
- Check for update at startup: When XL-ParseMails starts, check on website for available update of the tool.
- Open log file: The log file (XL-ParseMails.log) is located in the user directory. It is created when logging is enabled. It contains messages about errors that could happend when using the tool.
- Enable logging: Enable or disable logging of errors.
- In Functions section, you have the following options:
- Local timezone: When using Convert Datetime (ISO) option.
- Parse headers typical fields: Select fields to be used with Typical option in Parse Headers tab.
- Extract Typical fields: Select fields to be used with Typical option in Extract tab.
- Convert 6to4 addresses to IPv4: An IPv6 address that is used with 6to4 tunneling. An IPv4 address is appended to the prefix 2002::/16 to create the address. More information on https://en.wikipedia.org/wiki/6to4.